Dynamic Single Additive Manufacturing Machine Scheduling Considering Postponement Decisions:
A Lookahead Approximate Dynamic Programming
Abstract
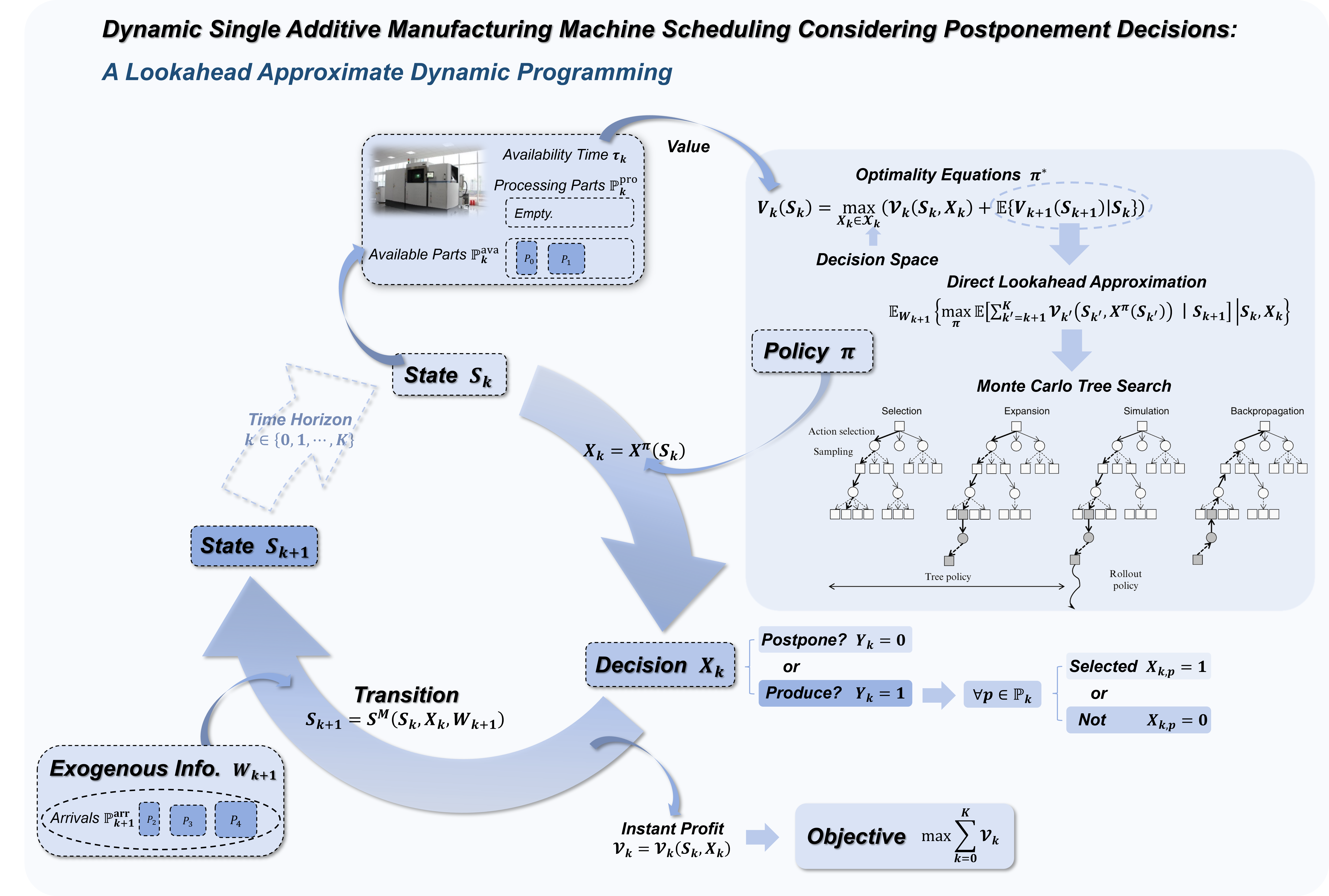
Additive Manufacturing (AM), facing challenges of high costs, is driving service providers toward social manufacturing by pooling distributed orders to amortize fixed expenses. However, for a single-machine operator in such environments, real-time scheduling under stochastic order arrivals presents a critical challenge: whether to process available jobs immediately to reduce tardiness or to strategically postpone production in anticipation of future arrivals for cost-efficient batch consolidation. We model this problem as a finite-horizon Markov decision process, where postponement is explicitly treated as a proactive choice, and the objective is to maximize long-term expected profit. To overcome the curse of dimensionality, we propose a lookahead approximate dynamic programming approach that evaluates the state values by simulating the future trajectories. The proposed approach integrates a Monte Carlo tree search framework for efficient lookahead tree evaluation, a one-step lookahead surrogate policy to guide rollout simulations, and a Pareto-based pruning strategy to focus on high-quality feasible decisions. Extensive numerical experiments demonstrate that the proposed policy outperforms conventional reactive rule and heuristics with static postponement thresholds, achieving an average empirical competitive ratio of 1.27 relative to the offline optimum.
Highlights
- Explicit Formulation: Modeled single AM machine scheduling problem as a finite-horizon Markov Decision Process where postponement is an active strategic choice.
- Lookahead Approximation Policy: Developed a Direct Lookahead Approximation policy utilizing Monte Carlo Tree Search for online decision-making.
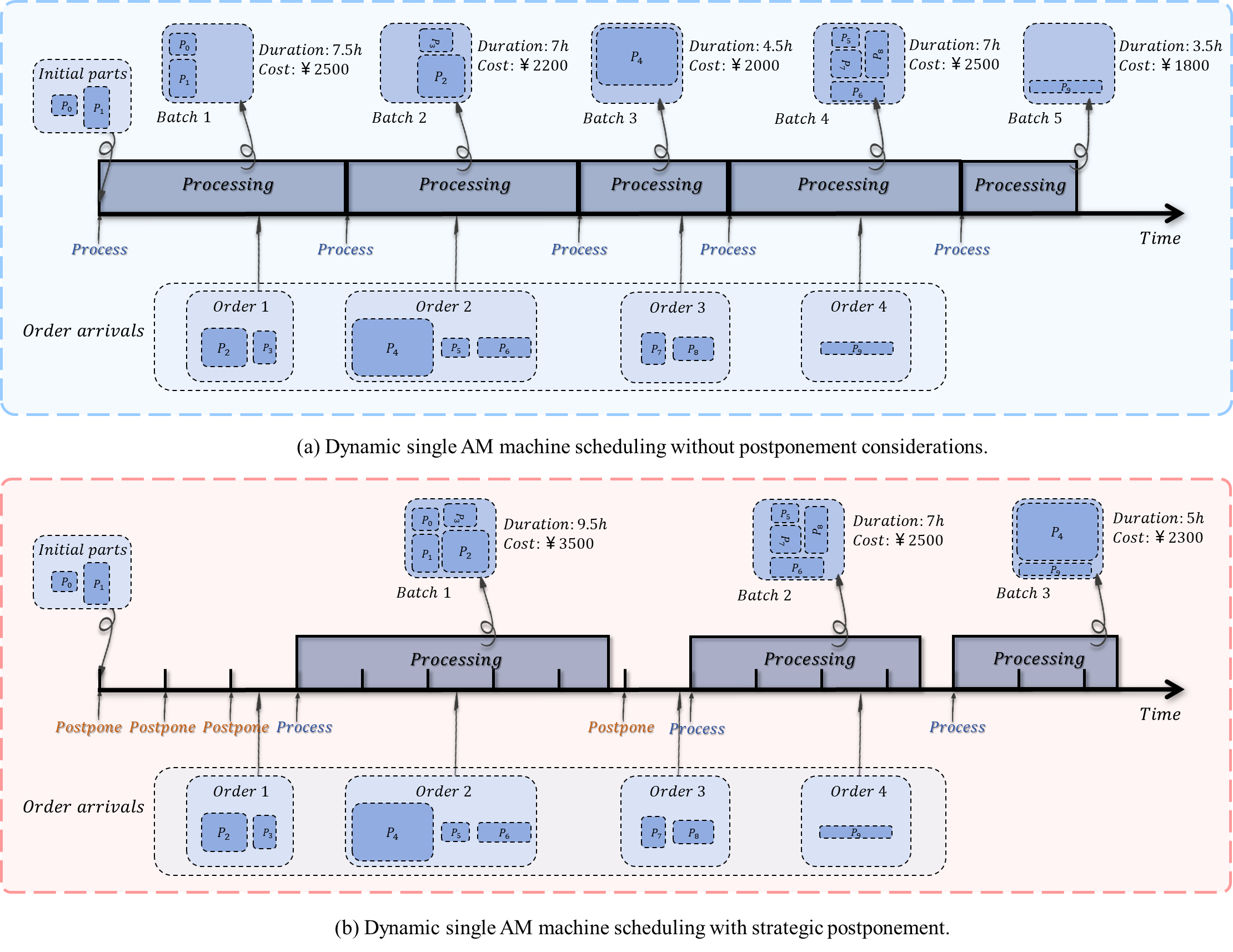
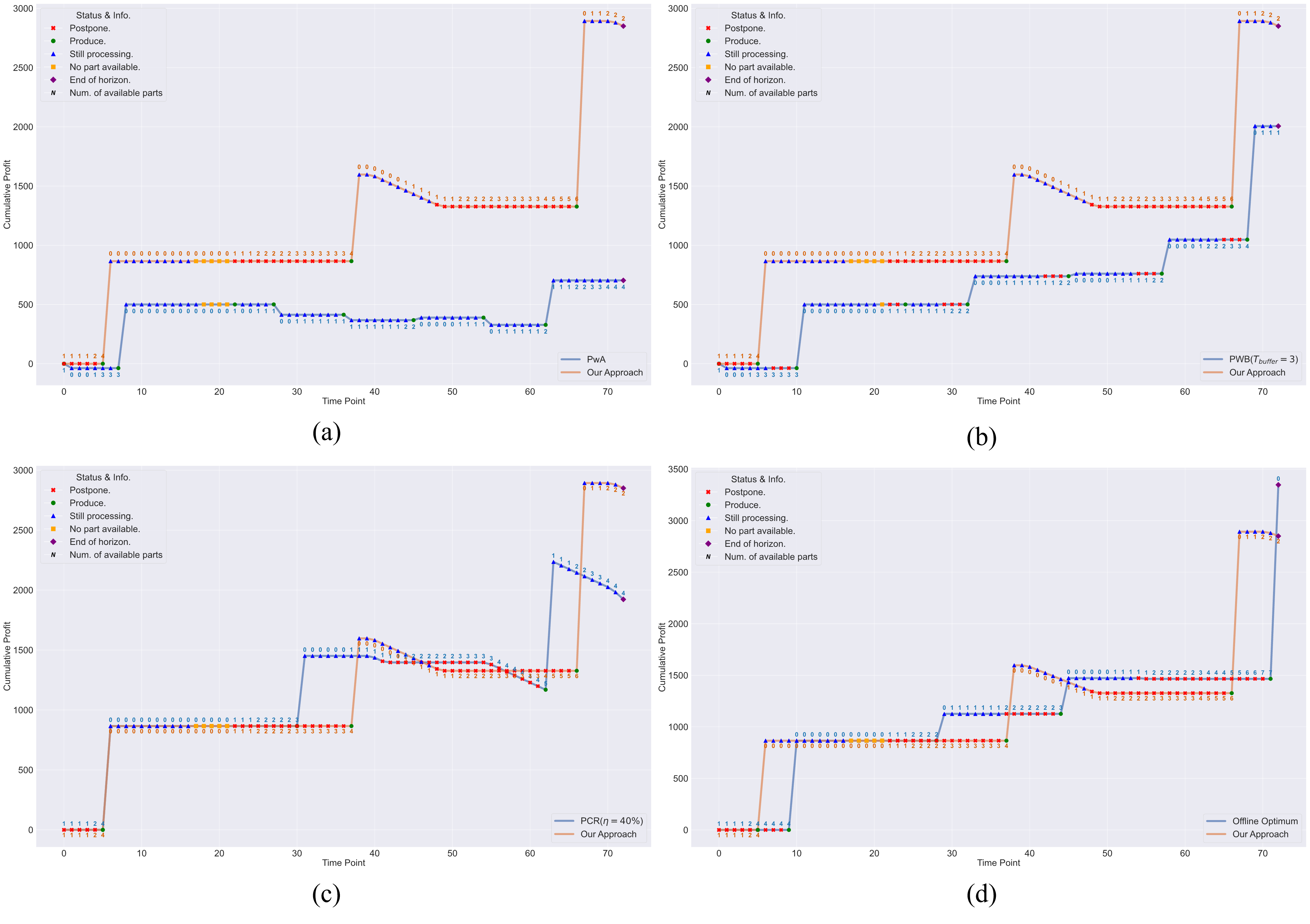
- Value of Postponement: Demonstrated how postponement decouples decisions with stochastic arrivals, filtering short-term noise to form high-density batches.
- Scalability: The approach provides high-quality solutions in real-time, effectively identifying "windows of opportunity" to consolidate orders without incurring excessive delays.
Key Features
The Scheduling Challenge
In Additive Manufacturing service bureaus, orders arrive stochastically. The operator must decide in real-time whether to Process the current batch immediately or Postpone to wait for more orders. This tradeoff balances the economies of scale (batching efficiency) against the risk of order tardiness.
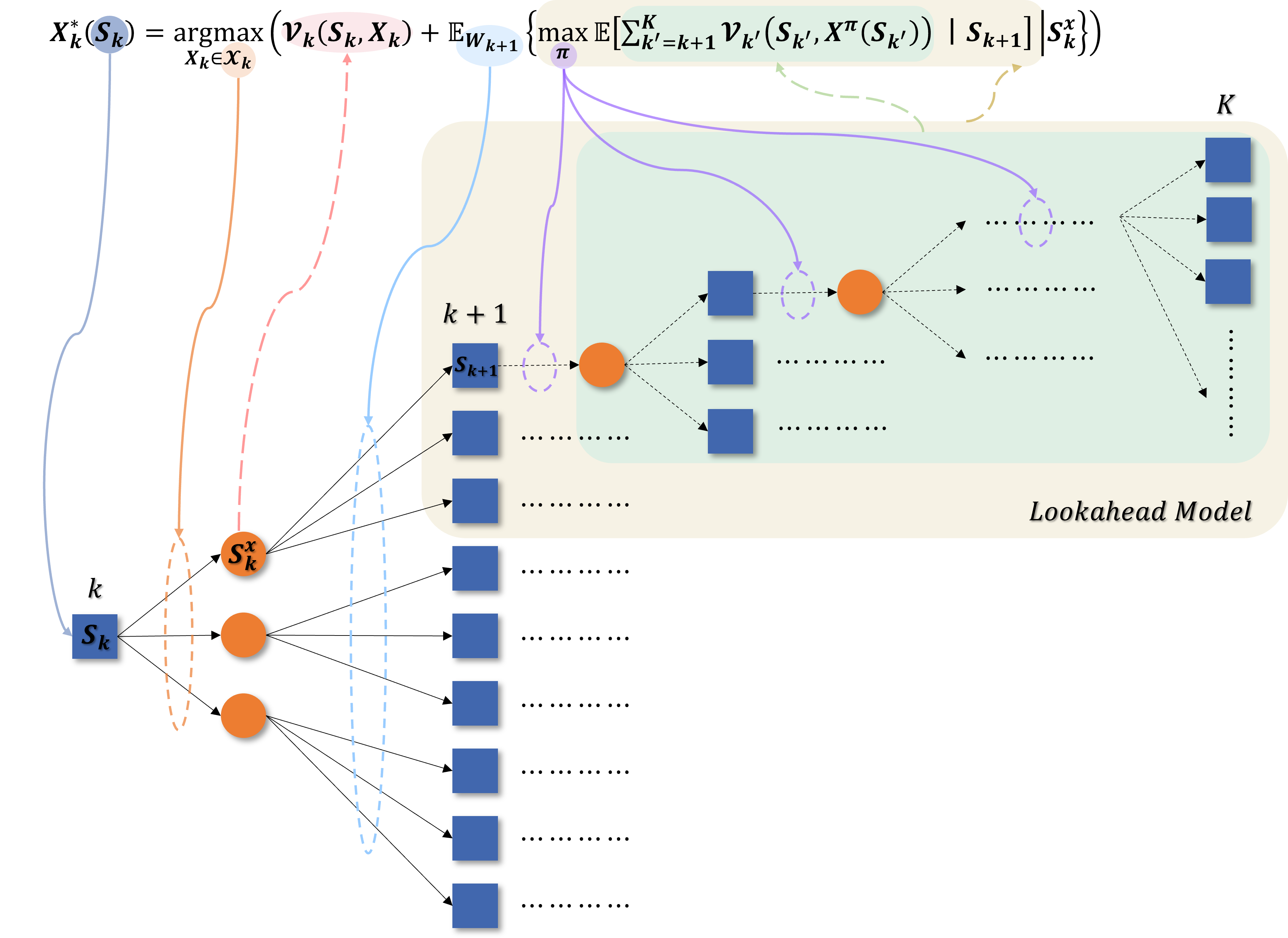
Approximate Dynamic Programming
We model the problem as a Markov Decision Process (MDP). To solve the curse of dimensionality, we employ a Direct Lookahead Approximation (DLA) policy. This uses Monte Carlo Tree Search (MCTS) to simulate future trajectories and estimate the value of current actions, enabling near-optimal online decisions.
Interactive Simulator
[Video Placeholder]
Replace with <video> or <iframe>
Try it yourself
We open-sourced the interactive simulator environment. You can visualize the postponing and batching process and test different policies.
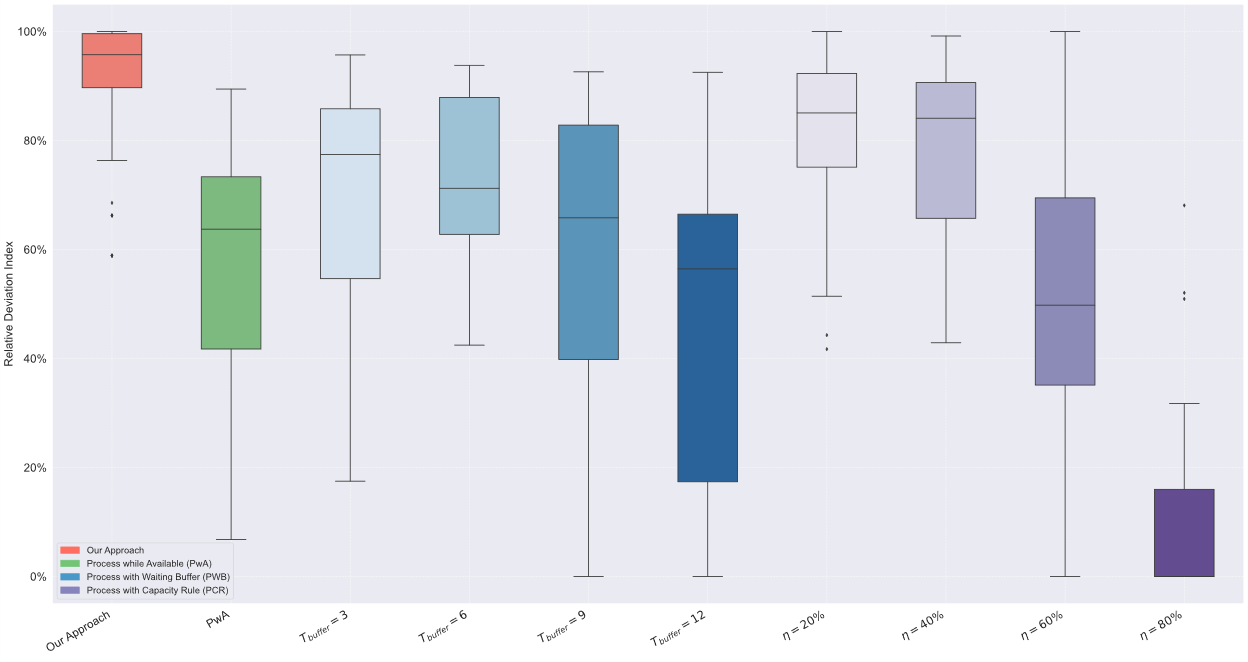
Launch SimulatorNumerical Experiments
Extensive numerical experiments demonstrate that the proposed policy significantly outperforms reactive scheduling rules and static heuristics, achieving an average empirical competitive ratio of 1.27 against the offline optimum.
Presentation Slides
Presented at IE Forum 2025.12.14, Tsinghua University.